
2019 loopt op z'n laatste benen. De Amerikaanse groei zal voor het tweede opeenvolgende jaar positief zijn. Hierdoor is deze expansie de langste sinds het midden van de 19de eeuw! De afgelopen jaren zijn de voorspellers zich door de ongebruikelijk lange duur van deze cyclus vaak vragen gaan stellen over een mogelijk nakende recessie. Ze volgen een eenvoudige redenering – hoe langer de expansie doorgaat, hoe hoger het risico dat ze stilvalt – maar dat is fout: zoals Janet Yellen al enkele jaren geleden aanhaalde, “sterven expansies niet van ouderdom”.
Dit jaar werd de vrees voor een recessie in de Verenigde Staten niet enkel ingegeven door dit risico dat de cyclus 'uitgeput' geraakt. De vrees is immers ook gevoed door de handelsoorlog, de vertragende groei in China en in de rest van de wereld, en de opkomst van de geopolitieke onzekerheid. Door de hardnekkigheid van deze dreiging, het opduiken van nieuwe risico's en de uitzonderlijk lange levensduur van deze cyclus is het best mogelijk dat de recessievrees in 2020 opnieuw de kop opduikt.
Hoewel de klassieke macro-economische analyse het mogelijk maakt om bronnen van instabiliteit te identificeren (accumulatie van macro-economische onevenwichten, het bestaan van zeepbellen van activaprijzen, enz.) en de schokken die mogelijk een economie in een recessie kunnen storten (handelsoorlog, te verstrakkend monetair beleid, enz.), laat ze niet toe om dit risico 'objectief' te meten. Om hiervoor een oplossing te vinden, hebben de economen en kwantitatieve beheerders van Candriam intern ontwikkelde kwantitatieve indicatoren ontworpen.
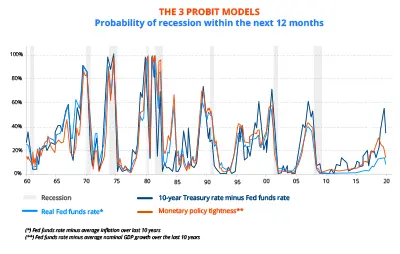
Lange tijd was de opbouw ervan gestoeld op zogenaamde 'probit'-modellen: afgeleiden van lineaire regressiemodellen. Deze modellen worden gebruikt wanneer de variabele die moet worden verklaard binair is. Ze laten het toe om in te schatten hoeveel kans er is dat één van beide gebeurtenissen zich zal voordoen, in dit geval de kans dat er al dan niet een recessie komt binnen een bepaalde termijn. Wanneer deze modellen gebruikt worden, hebben ze echter een belangrijke tekortkoming: modellen met een statistische kwaliteit geënt op het verleden kunnen aanleiding geven tot bijzonder uiteenlopende inschattingen voor het recessierisico. De keuze voor de verklarende variabelen speelt hier een bepalende rol, en stuurt in grote mate de vooruitzichten.
De inschatting van drie 'probit'-modellen die voornamelijk berusten op de steilheid van de rentecurve illustreert deze kwetsbaarheid. Terwijl in het verleden de steilheid van de curve, de reële kortetermijnrente en de soepelheid van het monetair beleid indicatoren bleken die ook een betrouwbare indicatie konden geven van een nakende recessie in de Verenigde Staten, lopen de signalen die al verschillende jaren worden uitgestuurd sterk uiteen... Aangezien we niet het 'goede' model kennen, kan de keuze voor een bepaalde van deze verklarende variabelen – die nochtans op een gelijkaardige manier evolueren – mogelijk leiden tot een verkeerde inschatting van het recessierisico.
GRAFIEK 1: de 3 'probit'-modellen
Om tegemoet te komen aan deze moeilijkheid, kunnen er meer gesofisticeerde – en robuuste! – modellen worden gebruikt. Twee ideeën liggen aan de grondslag van deze benaderingen:
- 'Oefening baart kunst': met andere woorden,je mag niets voor waar aannemen. Door deze modellen te trainen op verschillende gegevens kunnen we ze perfectioneren en hun voorspellend vermogen verbeteren.
- De 'wijsheid van de massa' of collectieve intelligentie: een diversiteit aan meningen, hun onafhankelijkheid en aggregatie (in tegelstelling tot de bewuste keuze voor één van deze meningen) zorgen ervoor dat een 'massa' intelligenter is dan gelijk welk individu in deze massa. Wanneer we dit toepassen op het voorbeeld dat ons interesseert, zorgt deze 'wijsheid van de massa' ervoor dat we de voorkeur geven aan de aggregatie van de gegevens die worden verstrekt door een veelheid aan gegevens die afkomstig is van gelijk wie in de massa. Met andere woorden, het is onnuttig om het beste model uit het verleden te zoeken, aangezien er geen enkele garantie is dat dit model ook in de toekomst het beste blijft. Het geniet dus de voorkeur om een grote diversiteit aan modellen te combineren, om er 'gemiddeld' betrouwbaardere informatie uit te halen.
Wij hebben twee methodes ontwikkeld, waarvan we de resultaten hieronder beknopt toelichten. Deze werden ontwikkeld op basis van een staal van zowat honderd economische en financiële variabelen die mogelijk de komst van een recessie binnen een termijn van één jaar kunnen voorspellen.
Eerste methode: 'Bayesan averaging of probit models'
Deze methode berust op de inschatting van honderdduizenden 'probit'-modellen die tot vier verklarende variabelen combineren, waaruit enkele tienduizenden modellen werden gekozen die economisch zinvol zijn. Net zoals een chirurg die, net voor een delicate operatie, een beslissing moet nemen op basis van een radiografie, worden deze modellen geëvalueerd op basis van de onzekerheid die gekoppeld is aan het opduiken van nieuwe omstandigheden. Met andere woorden wordt elk model geëvalueerd op probabilistische gronden. Dankzij de regel van Bayes kan de combinatie van modellen het mogelijk maken om een recessiewaarschijnlijkheid te verkrijgen die werd opgebouwd door een rationele redenering in aanwezigheid van onzekerheid.
Tweede methode: de random forests
De random forests zijn een willekeurige verzameling beslissingsbomen. Het idee van een beslissingsboom is dat de ruimte variabelen wordt onderverdeeld in homogene groepen, met andere worden dat de variabelen (en hun niveau) opeenvolgend worden gekozen om de evenementen die ons interesseren zo goed mogelijk te klasseren (een recessie zal plaatsvinden binnen één jaar... of niet).
In tegenstelling tot de 'probit'-modellen, zijn 'beslissingsbomen' niet-parametrische methodes die ons toelaten om rekening te houden met een grotere complexiteit van de interacties tussen de variabelen. Het gebruik ervan werd gedurende lange tijd afgeremd door hun instabiliteit: een beperkte wijziging van de modellen leidt tot de opbouw van zeer verschillende beslissingsbomen... en geeft dus zeer verschillende voorspellingen!
De associatie van het idee van de 'wijsheid der massa' met de vooruitgang op het vlak van artificiële intelligentie - meer bepaald 'machine learning', heeft sinds het begin van de jaren 2000 gezorgd voor de opkomst van een algoritme dat dit nadeel opheft: de random forests van beslissingsbomen. Zoals deze naam al aangeeft, is deze benadering niet gestoeld op het zoeken naar één enkele boom, maar op de aggregatie van een veelheid aan bomen (een bos), om de variantie en biases van de voorspellingen verder te verkleinen.
De reductie van de variantie wordt eveneens verzekerd door de implementatie van een leerproces van algoritmes op basis van subperiodes (hier komt de praktijk erbij kijken!) en de confrontatie van de voorspellingen met de geobserveerde realiteit buiten deze leerperiodes.
GRAFIEK 2: RF en Bayesian averaging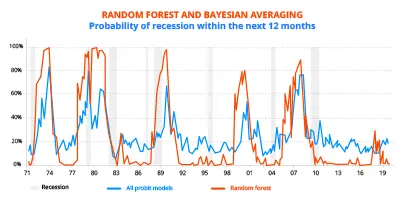
Deze twee methodes leiden vandaag tot een recessiewaarschijnlijkheid in de VS binnen 12 maanden die relatief zwak is. De Bayesian averaging pint deze vast op zowat 20%, een lichte stijging sinds eind 2017. De random forests van beslissingsbomen geven een nog meer uitgesproken resultaat, aangezien na een stijging richting 20% tussen eind 2017 en eind 2018, deze waarschijnlijkheid vandaag quasi nul is. De kwantitatieve analyse die wij hebben ontwikkeld, ondersteunt dus onze overtuiging als economen: ondanks de vertraging die we meemaken, zouden de Verenigde Staten in 2020 geen recessie mogen doormaken (cfr. artikel over vooruitzichten 2020 van 2 december).
